An Introduction to Potions
Potions are one of Squonk’s mega-features. They provide a simple language for performing arbitrary data transformations.
All too often the hardest part of a workflow is getting the data in shape in the first place. This is what potions were designed for. Using the simple declarative language you can perform a wide range of data transformations. For instance:
- Convert your tab or comma separated file containing smiles into proper molecules
- Converting text values to proper numbers
- Handling IC50 values that include qualifiers and/or ‘N/A’ values
- Converting numbers to log scale
- Performing simple mathematical operations
- Renaming fields
Let’s start with an example. One of our favourite datasets is a tab separated text file containing smiles and data. To make best use if it we need to convert the smiles to real molecules and transform various of the data fields. To do this we use this potion:
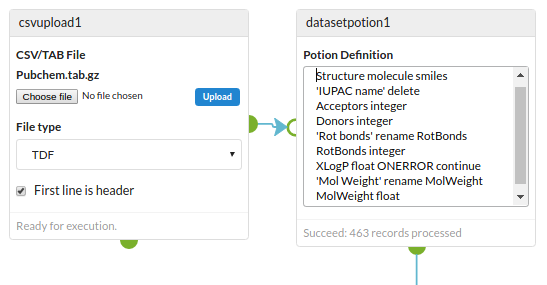
The potion is comprised of multiple statements, each on one line. It should be fairly obvious what is going on, but here’s a description:
- Convert to molecules using the Structure field which is in smiles format
- Delete the IUPAC Name field
- Convert the Acceptors field to integer data type
- Convert the Donors field to integer data type
- Rename the ‘Rot Bonds’ field to RotBonds to remove the space in the field name
- Convert the XLogP field to float data types ignoring any values that fail to convert
- Rename the ‘Mol Weight’ field to MolWeight to remove the space in the field name
- Convert the MolWeight field to float data types
Much more is possible, and this simple example only scratches the surface.
Using Potions
To use a potion locate the DatasetPotion cell from the cell palette (hint: search for potion) and add it to the notebook canvas. Connect the input and output, specify the potion in the text area and execute.
Potion Language Definition
Basic syntax
A potion is made out of one or more potion commands. Each command is a separate line.
LogP float ONERROR continue
A line starting with # is a comment and ignored.
# a comment
Blank lines are ignored
Record level commands
Some commands work on the whole record.
delete
This deletes every record. Not very useful!
delete IF <condition>
This deletes the record if the condition is met. See below for more details of the syntax for conditions, but for now an example should suffice:
delete IF LogP > 5
As you might expect this deletes the record if the value of the field named LogP is greater than 5.
Field transform commands
These commands transform the data for a particular field. The basic syntax is:
<fieldname> <newdatatype> ONERROR fail|continue
The ONERROR part is optional and determines what happens if the value for a particular record cannot be converted. The ‘fail’ option (which is the default if no ONERROR statement is present) means that the whole process will fail. The ‘continue’ options means ignore the failures and remove those values (set to null). For instance, if the field you want to convert to integers contains some values that are invalid (e.g. non numbers) then you can use this to convert those that convert and omit those that don’t:
BondCount integer ONERROR continue
Field names must be quoted (single or double quotes) if they contain spaces. As a caution, field names with spaces are likely to cause problems, so you are advised to rename them so that they do not contain spaces (see the field rename command below).
"Bond Count" integer ONERROR continue
The supported types are:
<fieldname> integer
<fieldname> float
<fieldname> double
<fieldname> text
<fieldname> string
<fieldname> molecule <format>
<fieldname> qvalue float
<fieldname> qvalue double
<fieldname> qvalue integer
All but the molecule take an optional ONERROR statement, allowing invalid values to be ignored. In order these commands do the following:
- integer: convert to an integer value (number with no decimal component)
- float: convert to a 32 bit floating point number
- double: convert to a 64 bit floating point number
- text: convert to text
- string: a synonym for text
- molecule: convert BasicObject to MoleculeObeject using the specified field for the structure and specifying that the structure is in stated format (supported formats are smiles and mol)
- qvalue: convert to a QualifiedValue of the specified numeric type (see below for more about QualifiedValues)
Field Assignment commands
These are the most powerful and complex commands, allowing fields to be defined using ‘formulas’. The basis syntax is as follows:
<fieldname> = <expression>
<fieldname> = <expression> IF <condition>
<fieldname> = <expression> IF <condition> ONERROR fail|continue
<fieldname> = <expression> ONERROR fail|continue
Expression
In all cases there us the field name followed by an equals sign and an expression. The expression is evaluated as Groovy code, with the filed variables for the record magically injected so that they can be evaluated. The expression can be simple or complex. Here are some examples:
fld1 = fld2 <- simple assignment of fld1 to the value of fld2
fld2 = fld1 * 10 <- fld2 is assigned to fld1 times 10
fld3 = fld1 + fld2 <- fld3 is assigned to fld1 plus fld2
fld4 = log10(fld1) <- fld4 is assigned to the base 10 logarithm of fld1
fld5 = min(fld1, fld2) <- fld5 is assigned to the minimum of fld1 and fld2
fld6 = fld2.toInteger() <- fld6 is assigned to the integer value of fld1
Variable names to the left of the # operator can have spaces if they are enclosed with single or double quotes, but this does NOT apply to variables to the right of the . They should be renamed (see above).
The assignment of fld4 and fld5 uses methods from the java.lang.Math class which are imported (using a static star import) to make them easily accessible (without this they would need to be accessed using more clumsy syntax like Math.log10(fld1), though this type of syntax can be used to access static methods of other Java or Groovy classes).
Condition
The condition is an optional part after the IF term and before the ONERROR term (if present). Note it must be uppercase IF to allow it to be distinguished from the if keyword that can be part of Groovy language. A condition, like an expression is evaluated as a Groovy expression and if evaluated first, and if it evaluates to true then and only then is the expression part evaluated. This allows for conditional execution. Here are some examples:
fld1 = fld2 IF fld2 <- assign fld1 if the value of fld2 evaluates as true
fld2 = fld1 IF fld4 <- assign fld2 if the value of fld4 evaluates as true
fld3 = fld1 + fld2 IF fld1 < 4 <- assign fld3 if the value of fld1 is greater than 4
fld4 # fld1 + fld2 IF fld1 ! null <- assign fld3 if the value of fld1 is defined
When the IF condition is evaluated the result is always handled as true or false. Groovy is smart about this and can coerce numbers and strings to true/false values (e.g. zero is treated as false and any non-zero number as true). This is what is happening in the fld1 and fld2 assignments in the above example. For a full definition see Groovy Truth.
On Error
There can be an options ONERROR statement following the expression or condition. Note that is a condition is present the ONERROR MUST follow the condition. The ONERROR part defines what to do when executing the expression (not the condition) causes an error, in a way similar to that seen above for field transform commands. It can have values of fail or continue, with the behaviour being fail if no ONERROR clause is present. As an example:
fld1 = fld2 IF fld2 ONERROR continue <- continue on errors
fld1 = fld2 IF fld2 ONERROR fail <- fail on errors
fld1 = fld2 IF fld2 <- fail on errors
Other aspects
A field’s values must be homogeneous in data type - all records must be the same datatype (e.g. all integers or all strings, not a mixture of integers and strings). When using conditional assignments it is potentially possible to break this rule which will cause errors, so be careful.
If the operation you are wanting to perform is very complex you might be better using a Groovy or Python script. Potions are supposed to be fairly simple.
Handling errors are an inherent problem as they can sometimes be a bit cryptic. If you are having problems break it down into multiple steps.
Other Field Commands
Rename
This simple command renames a field. Here are some examples:
fld1 rename 2
"fld 1" rename fld1
Replace values
This command allows to replace values with other values. This can be useful when cleaning up data that has annoying text values. Here are some examples:
fld1 replace N/A null <- replaces any values that match N/A with null (e.g. removes them)
fld2 replace 1 2 <- replaces all values that are 1 with 2
fld2 replace null 0 <- replaces all missing values with zero
The match and replace values are converted to the correct type for the field. For instance, in the second example, assuming that fld2 is of type integer then the values 1 and 2 are handled as integers. The terms ‘null’ is a special keyword that means the null object e.g. in the first example all occurrences of N/A are converted to the null object and so effectively removed.
Delete values
This command let’s you delete values from records. It comes in 2 flavours:
fld1 delete
fld2 delete IF <condition>
The first variant will delete the field from all records, so that the field is no longer present. The second variant allows for conditional deletion of values by specifying an ID clause which is handled in the same way as it is during assignment. For instance:
fld1 delete IF fld2
fld2 delete IF fld2 > 10