CATEGORY
Transform
SOURCE
Squonk
DESCRIPTION
Enriches one dataset with content from another
INPUTS
Two datasets of any type.
OUTPUTS
A single dataset containing data from the first updated with values from the second.
OPTIONS
| Input field name | The name of the field in the “input” dataset for the common IDs. If not defined the UUID will be used. |
| NewData field name | The name of the field in the “newData” dataset for the common IDs. If not defined the UUID will be used. |
| Mode | Defines how the merging is performed. Options are main, values and both. |
ADDITIONAL INFO
The purpose of this cell is to allow one dataset to be enriched with data from a second dataset. Information form the second is merged into the first.
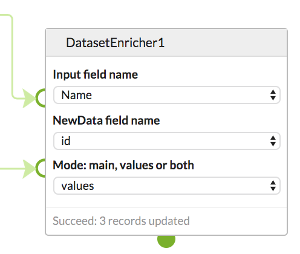
The data that is merged can be the core information (e.g. the source and format for a Dataset of MoleculeObjects) or the values or both. The datasets do not need to be of the same type, but if they are different only the values can be merged.
The records can be matched based on a field name or if not specified by the UUID. Records in the second dataset not present in the first (e.g. identified by the field name or UUID) are ignored. Where data is common between both records (e.g. both contain values for a specific field) the data in the first dataset is replaced with that from the second. The result is all the data in the first dataset “overlaid” with any data from matching records in the second. What is merged is controlled by Mode option which allows to specify to merge just the main content (e.g. structure info for a MoleculeObject), just the values or both the main content and the values. If datasets are are different types then only the values can be merged.