CATEGORY
Transform
SOURCE
Squonk
DESCRIPTION
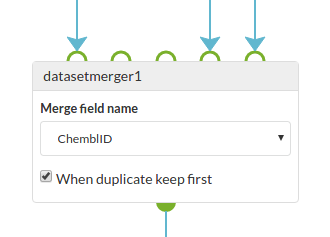
Merge multiple datasets into one using a common key. Useful for combining data from multiple sources into a single dataset where there is a common identifier linking the records
INPUTS
This cell accepts up to five input datasets which must all be of the same type
OUTPUTS
The single output is the merged data
OPTIONS
| Merge field name | The name of the field that contains the keys that identify the common records in the input datasets. If none is specified the objects UUID is used which is probably not what is wanted. |
| When duplicate keep first | How to handle duplicate properties that are encountered when merging - keep the current one or use the new one. |
ADDITIONAL INFO
Merging is done by first processing each input in turn (1, 2, 3, 4, 5). Whenever a duplicate key is encountered for the “Merge field name” field the properties from the new record are merged to those of the existing record (according to the “When duplicate keep first” setting). Duplicates can occur within a dataset as well as between datasets. If the key does not already exist the new record is added to the resulting dataset.
The result is that records with duplicate keys are removed from the resulting dataset but their properties are merged with the existing ones.